
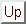

Now we'll implement the scheme described above to carry out non-linear regression as a succession of linear regressions in this case study. We begin by defining the model form (called f below). Following that, we compute the partial derivatives (and name them). In xlispstat I can do that as follows:
(defun f(x gamma alpha beta) (* gamma (exp (- (/ alpha (^ x beta))))) ) (derfunc fpg f gamma) (derfunc fpa f alpha) (derfunc fpb f beta)
Now we'll use the model form, and the data, to compute estimates for the
responses (the cumulatives minus the estimates). We use the three vectors of
the partials evaluated at the data (hours) and at the current best parameter
values (the vector containing ![]() ).
).
;; find parameters for cumulatives versus hours:
(let* (
(n (length hours))
(gammas (repeat gamma n))
(alphas (repeat alpha n))
(betas (repeat beta n))
(estimates (mapcar #'f hours gammas alphas betas))
reg new-coefs coefs
)
(setq reg (regress (list
;; these are vectors of partial derivative values
(mapcar #'fpg hours gammas alphas betas)
(mapcar #'fpa hours gammas alphas betas)
(mapcar #'fpb hours gammas alphas betas)
)
(-
(cumsum bodies)
estimates
)
:intercept nil
)
new-coefs (send reg :coef-estimates)
coefs (+ (list gamma alpha beta) new-coefs)
gamma (first coefs)
alpha (second coefs)
beta (third coefs)
)
(list gamma alpha beta)
)
The first six iterates are given in the appendix. They agree with the results obtained using the non-linear regression program used above.
If we redo the linear regression analysis using the value of 124.38 rather than 120 (which was ad hoc), we see that the linear regression results improve a little (a smidgen, but then they didn't have much room for improvement - they're already excellent):
Linear Regression: Estimate SE Prob Constant 2.96654 (8.280051E-2) 0.00000 Variable 0 -2.12767 (4.222013E-2) 0.00000 R Squared: 0.996078 Sigma hat: 8.198243E-2 Number of cases: 12 Degrees of freedom: 10
versus
Linear Regression: Estimate SE Prob Constant 3.26870 (0.129672) 0.00000 Variable 0 -2.39415 (6.612010E-2) 0.00000 R Squared: 0.992431 Sigma hat: 0.128391 Number of cases: 12 Degrees of freedom: 10