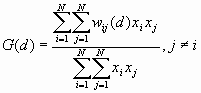
The General G(d) Statistic
The General G(d) statistic is a multiplicative measure of overall spatial association of values which fall within a given distance of each other. It was developed by Getis and Ord (1992).
Input
Analysis
A G(d) value higher than the expected G(d) indicates a clustering of high values, and a G(d) lower than the expected G(d) indicates a clustering of low values. The variance of G(d) and a Z-value (standard variates) are calculated to determine the level of significance.
Formula
For a chosen critical distance d, G(d) is
where ![]() is the value of the ith point and
is the value of the ith point and
![]() is the weight for point i and j for distance d.
is the weight for point i and j for distance d.
The expected mean value of G(d) is
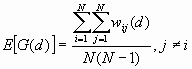
The variance of G(d) is
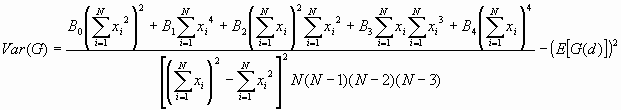
where
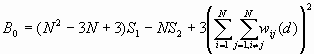
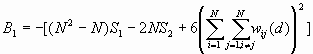
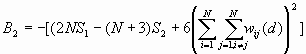
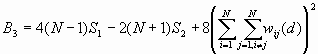
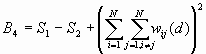
![]()
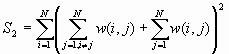
The Z-value is calculated as:
![]()
Output
Example
For this example we will consider the distribution of AIDS rates for the counties of California. The data are taken from the Department of Health Services of the State of California (1999). The rates are cumulative incidences since 1981 per 100,000 population. The data are shown in Table 1. A map showing the AIDS rates by county is shown in Figure 1.
Table 1: Cumulative AIDS rates of California Counties 1981-1999
|
County |
X |
Y |
Rate |
|
Alameda |
195 |
500 |
389.13 |
|
Alpine |
318 |
560 |
0.00 |
|
Amador |
265 |
550 |
99.37 |
|
Butte |
220 |
630 |
85.86 |
|
Calaveras |
280 |
530 |
29.70 |
|
Colusa |
195 |
598 |
62.38 |
|
Contra Costa |
192 |
515 |
222.30 |
|
Del Norte |
100 |
790 |
61.57 |
|
El Dorado |
260 |
580 |
87.65 |
|
Fresno |
320 |
425 |
119.26 |
|
Glenn |
180 |
630 |
31.57 |
|
Humboldt |
90 |
705 |
132.20 |
|
Imperial |
648 |
56 |
75.39 |
|
Inyo |
450 |
403 |
56.38 |
|
Kern |
396 |
256 |
130.65 |
|
Kings |
315 |
380 |
144.30 |
|
Lake |
155 |
597 |
184.04 |
|
Lassen |
270 |
710 |
141.50 |
|
Los Angeles |
436 |
168 |
403.26 |
|
Madera |
315 |
455 |
71.84 |
|
Marin |
175 |
510 |
568.01 |
|
Mariposa |
305 |
485 |
67.43 |
|
Mendocino |
125 |
602 |
173.02 |
|
Merced |
285 |
470 |
56.90 |
|
Modoc |
265 |
765 |
9.23 |
|
Mono |
380 |
515 |
18.48 |
|
Monterey |
212 |
415 |
186.08 |
|
Napa |
185 |
545 |
151.79 |
|
Nevada |
255 |
610 |
118.37 |
|
Orange |
468 |
112 |
188.78 |
|
Placer |
270 |
595 |
57.22 |
|
Plumas |
272 |
660 |
27.49 |
|
Riverside |
600 |
120 |
239.32 |
|
Sacramento |
235 |
548 |
219.73 |
|
San Benito |
220 |
430 |
63.14 |
|
San Bernadino |
584 |
216 |
140.66 |
|
San Diego |
544 |
52 |
353.04 |
|
San Fransisco |
185 |
503 |
3041.87 |
|
San Joaquin |
236 |
520 |
120.20 |
|
San Luis Obispo |
272 |
260 |
177.28 |
|
San Mateo |
190 |
490 |
246.13 |
|
Santa Barbara |
300 |
200 |
151.54 |
|
Santa Clara |
202 |
475 |
177.01 |
|
Santa Cruz |
200 |
450 |
185.09 |
|
Shasta |
197 |
712 |
65.25 |
|
Sierra |
275 |
630 |
119.40 |
|
Siskiyou |
180 |
782 |
68.14 |
|
Solano |
192 |
540 |
252.59 |
|
Sonoma |
170 |
535 |
352.65 |
|
Stanislaus |
265 |
491 |
108.42 |
|
Sutter |
210 |
590 |
61.69 |
|
Tehama |
193 |
680 |
37.35 |
|
Trinity |
140 |
702 |
77.64 |
|
Tulare |
365 |
385 |
57.78 |
|
Tuolumne |
303 |
515 |
92.80 |
|
Ventura |
372 |
176 |
99.11 |
|
Yolo |
205 |
570 |
91.98 |
|
Yuba |
228 |
604 |
71.66 |
Figure 1: Cumulative AIDS Rates of California Counties
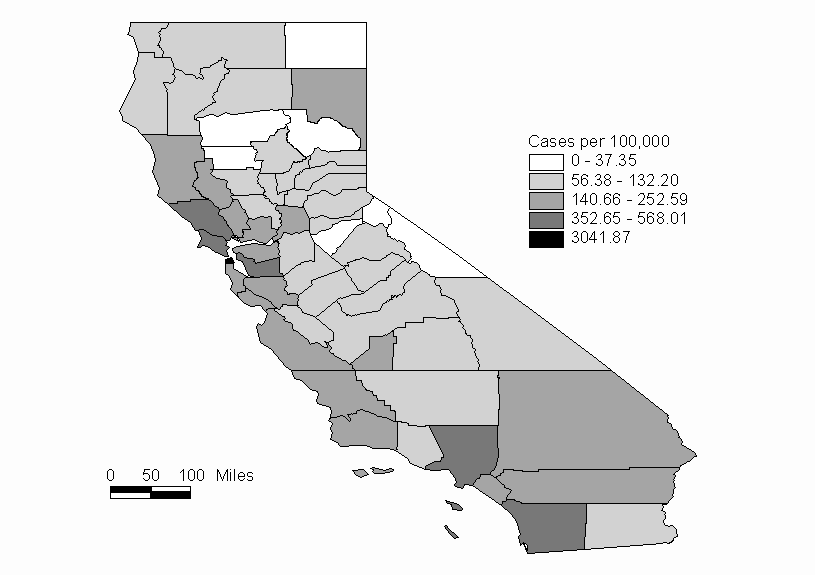
The G(d) statistic is computed for 50 mile increments from 50 to 250 miles. The output file is shown as Table 2. The highest Z-value (4.93) is found at a distance of 50 miles, and the Z-values decrease as the distance is increased. The Z value from the tables of the normal distribution for a =0.05 (2-tail) is +/-1.96. At the a =0.05 level, there is significant clustering of high AIDS rates for distances of 50 and 100 miles. This clustering is most evident in the San Fransisco Bay area (Figure 1). As the distance of study is increased, the clustering tendancies of high AIDS rates decrease.
Table 2: Output
The input data file: aids.dat
The total number of points: 58
Distance G(d) Expected G(d) Variance Z-value
50.0000 0.19054 0.0587 0.00071 4.9314
100.0000 0.35785 0.2202 0.00483 1.9814
150.0000 0.49061 0.3975 0.00983 0.9393
200.0000 0.57358 0.5299 0.01149 0.4070
250.0000 0.64102 0.6231 0.01116 0.1696
References
Getis, A. and Ord, J.K. (1992) The Analysis of Spatial Assosciation by Use of Distance Statistics, Geographical Analysis, 24: 189-206.
Getis, A., and Ord, J.K. (1998), "Spatial Modelling of Disease Dispersion Using a Local Statistic: The Case of AIDS," Chapter 12 in D.A. Griffith, C.G Amrhein, and J-M Huriot (eds.) Econometric Advances in Spatial Modelling and Methodology: Essays in Honour of Jean Paelinck, Kluwer.
State of California Department of Health Services (1999). 1998 Report Health Data Summaries for California Counties.